이번 글에서는 NeurIPS에 Spotlight로 선정된 “Temporal Spike Sequence Learning via Backpropagation for Deep Spiking Neural Networks” 논문을 소개해드리려고 합니다.
해당 논문의 자세한 내용은 링크와 github를 참고해주세요
Introduction
- Spiking Neural Network(SNN)은 뇌의 행동을 모방하여 동작할 수 있는 모델로 기존 DNN(Deep Neural Network)와 달리 Time data 또한 영향을 끼치는 모델입니다. 최근 DNN의 많은 에너지 사용 대신 효율적으로 사용하는 뇌를 모방하여 전성비를 올리기 위한 목적으로 Neuronmorphic chip과 더불어 SNN이 개발되고 있습니다.
- DNN의 학습 방식은 gradient descent 기반의 back propagation이 대세이지만, SNN에서는 local 정보를 기반으로 하는 STDP와 SRDP방식과 DNN의 backpropagation방식을 모방한 방식으로 나뉘어 있습니다.
- SRDP(Spike-Rate Dependency Plasticity)의 경우, presynaptic neuron과 postsynaptic neuron사이의 activation 빈도가 높을 때, 서로의 connection을 강화하는 방향으로 학습하며, STDP의(Spike-Time Dependency Plasticity)는 presynaptic neuron과 postsynaptic neuron 순으로 activation time의 사이 간격이 좁을수록 connection을 강화하고 postsynaptic neuron의 activation이후 presynaptic neuron의 activation이 일어나면 connection을 약화하는 방식으로 진행됩니다.
- 이 논문은 STDP의 connection 강화 측면과 DNN의 Back Propagation(BP) method를 활용하여 학습을 효율적으로 진행할 수 있는 방법론을 제시하였습니다.
Background
- SNN을 적용하기 위한 Hardware(Neuromorphic Chip)의 발전은 빨랐지만, 기존 DNN과 비교할 때 성능이 낮았고, 5개 layer를 넘어가면 저조한 성능을 보이는 등 그를 적용하기 위한 모델의 발전은 더뎌왔습니다.
- 기존의 연구들은 DNN을 학습시킨 후, SNN을 변환하는 시도가 있어왔고, Spike를 통해 다음 neuron에 정보를 전달하는 하는 SNN의 Discrete property를 back propagation에 사용하기 위해 continuous하게 smoothing하여 approximate하는 모습을 보여왔습니다.
- 하지만 이러한 시도들은 All-or-None characteristic을 가진 neuron의 특징 상, smoothing은 target과 precision간의 loss 연산에 있어서 낮은 accuracy를 보였습니다. 또한, approximation한 후의 정확한 spike timing을 알기 위해서 precision에서 많은 time을 요구하여 latency가 발생하는 단점이 있었습니다.
Proposed Model
- Discrete LIF(Leaky Integrated-and-Fire) Model 기반의 모델을 사용하여 Discontinuity하여 non-differentiable을 해결하고자 하였습니다. 기존의 LIF Model이 갖는 모델의 공식은 다음과 같습니다. Spike s에 대한 공식이며, firing하는 시간 t에 대해서 delta함수를 가져 discrete하게 나타남을 알 수 있습니다.
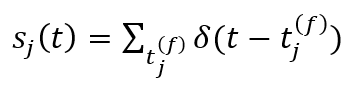
- 또한, postsynaptic current(PSC) a_j(t)에 대해서 incoming spike s_j(t) 는 다음과 같은 1차 미분 관계식을 갖습니다. (Spike response: ϵ , Reset kernel: v )
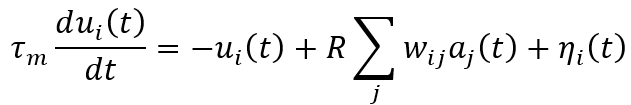
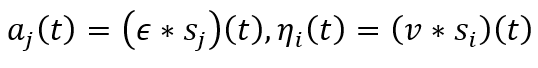
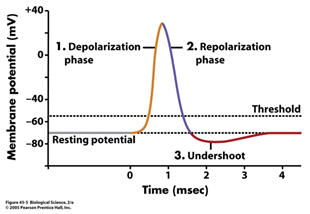
- 즉, presynaptic neuron j에서 postsynaptic neuron i로 PSC가 전달되어 weight에 의해 가중합이 된 것이 postsynaptic neuron의 membrane voltage u_i 가 변화함을 알 수 있습니다. 이렇게 변화한 voltage는 threshold Vth를 넘으면 spike s_i 가 발생하며 뇌에서 일어나는 탈분극, 재분극, 분극 상태처럼 동작하게 됩니다.
- 위 식을 discrete domain으로 옮기면 LIF model은 다음 식처럼 나타낼 수 있습니다.
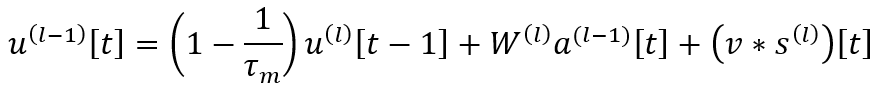
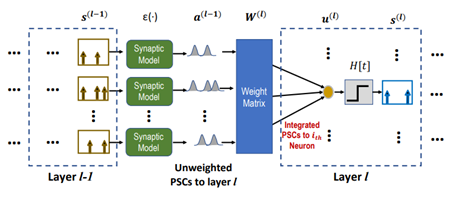
- 이렇게 제안된 model을 바탕으로 back propagation을 spatiotemporal domain 기반으로 discontinuity를 갖는 spike를 계산할 수 있습니다. 각 layer의 weight는 Loss기반으로 연산 가능하므로 DNN에서의 back propagation과 유사하게 chain rule을 적용하여 풀이할 수 있습니다.
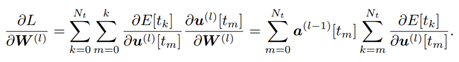
- 이 식을 hidden layer에서 풀면, 식에 대해서 Loss값의 미분은 아래와 같은 layer l 에 대한 식으로 연결됩니다.
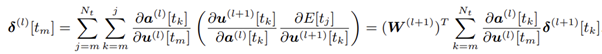
- 하지만, 모든 시간에 대해서 계산한다면 deep SNN에서 time step수만큼의 모든 neural network를 계산해야 하므로 기존 DNN보다 복잡도가 time step수 배만큼 늘어나게 됩니다. 이러한 상황을 억제하기 위해서 논문에서는 2가지의 dependency로 나누어 back propagation method를 제시합니다.
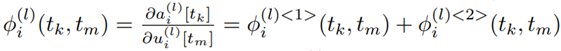
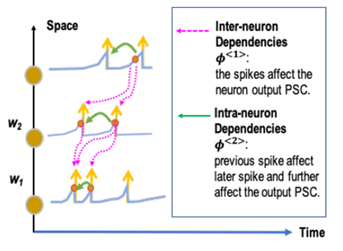
- Inter-Neuron Dependency
A. Postsynaptic Current의 증가는 Presynaptic neuron의 발화로부터 오기 때문에, 발화시점의 전압 변화량은 PSC의 변화에 영향을 준다는 의미이며, Postsynaptic Current를 조정하는 weight는 발화 시점 이후만 연산하면 된다는 의미입니다. 아래 식처럼 발화 시점 t_m 을 기점으로 시간의 변화가 t_k시점의 current변화에 영향을 미치기 때문에 이외의 시간을 중심으로 미분하여 구할 필요가 없다는 의미이기도 합니다.
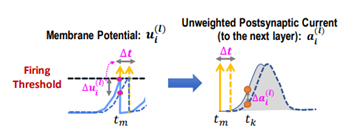
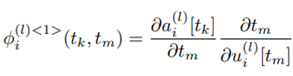
- Intra-Neuron Dependency
A. Intra-Neuron은 자신의 발화에 관한 것으로 자기 자신이 fire(발화)를 했을 때, 이후 몇 step동안엔 fire를 reset kernel에 의해 못하게 된다. 이러한 시간 동안에는 연산의 필요성이 없으므로 이를 배제하고 연산하면 된다는 것이다. 예를 들어 t__m 시간에 fire를 하고, reset 시간 도중에 fire가 불가능하므로 그동안은 연산에서 제외하여 불필요한 연산을 줄일 수 있습니다. η_i(t) 가 이러한 membrane potential의 reset에 관여하며 다음과 같은 식에서 전압의 변화에 영향력을 행사합니다.
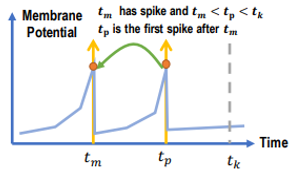
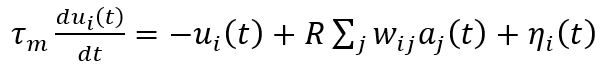
모델을 기준으로 식을 풀어쓰면 Intra-Neuron Dependency는 다음과 같습니다.
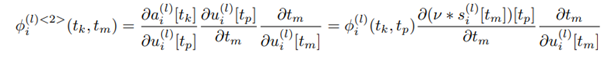
3. Dependency Combination
- 이러한 Dependency를 결합하여 chain rule에 사용되는 term을 구하여 쓸모없는 구간에서 기억하고 연산하는 것을 막으므로 시간을 절약할 수 있다고 저자는 말하고 있습니다. 아래의 식처럼 Firing 여부에 따라 해당 term이 연산되며, back propagation이 chain rule에 의해서 진행되는지 되지 않는지 확인할 수 있게 됩니다.
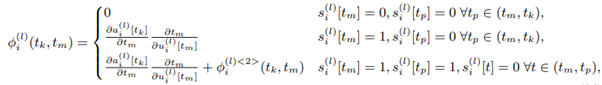
Experiment
- 실험의 결과는 다음과 같이 타 SNN의 BP와 비교할 때, 앞서 논문에서 언급한 것처럼 이전 논문들의 긴 time step을 극복하고 짧은 time step 내로 높은 accuracy를 달성하여 precision delay를 줄일 수 있는 결과를 확인할 수 있었습니다. 이를 통해 학습 시간도 단축하여 SNN의 등장 목적을 달성할 수 있을 것이라고 말하고 있습니다.
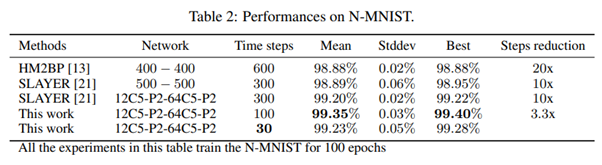
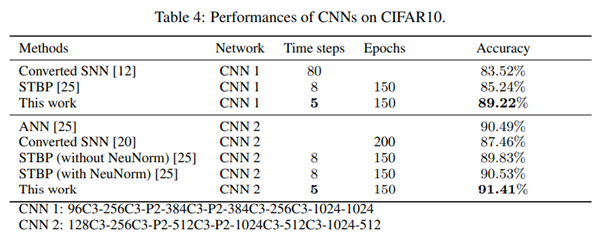
- SNN의 특징인 일부만 Firing을 실행하여 energy efficiency를 달성하는 데에 있어서 얼마나 잘 달성했는지 CIFAR10과 N-MNIST에 대해 비교하였으며, 이를 현재 DNN에서의 pruning을 연구하는 사람들의 관점에서 바라봤을 때, 많은 node를 pruning하여 sparsity를 달성하여 mobile환경에서도 사용시에 어떤 관점으로 바라봐야 할지에 대한 다음의 실험 결과도 확인할 수 있었습니다.
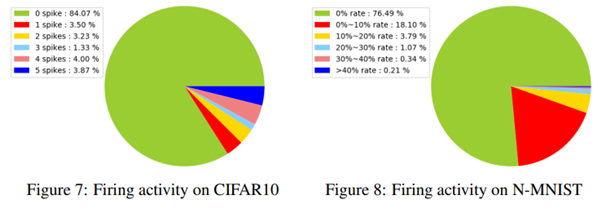
Conclusion
- 본 논문에서 제안된 방법은 SNN에서 DNN의 Back Propagation Method를 어떻게 끌고 와서 학습시킬지에 대한 내용으로 실제 SNN의 동작방식과 달라 SNN에서 학습시키기 어려운 단점이 있습니다. 하지만, 학습 후, 적절하게 SNN으로 옮겼을 때, 기존의 연구들과 달리 dependency를 두개로 나누어 back propagation시에 적은 time step내로 학습시키는 방법과 feed forward에서 prediction하는 방법에 대해서 제시하고 있습니다. Dependency를 통해 실제 뇌에서 일어나는 탈분극과 재분극의 과정에서 Non-activate되는 시점을 잘라냄으로써 time step의 수를 줄여낸 연구라고 할 수 있습니다.
자세한 내용은 full paper를 참고하거나 댓글로 남겨주세요.
감사합니다.