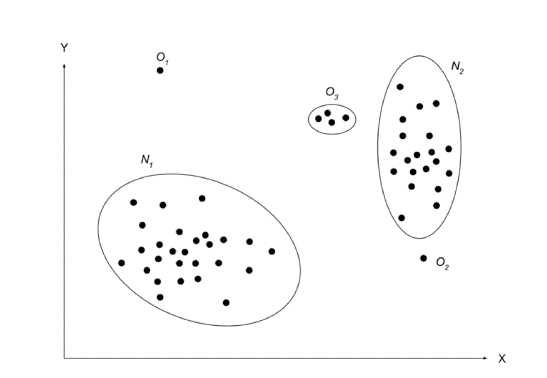
이번 글에서는 Anomaly Detection에 대한 간략한 소개와 함께 GAN을 Anomaly Detection에 처음으로 적용한 논문을 리뷰하겠습니다. 논문 원제는 Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery 이며, Anomaly Detection 소개 부분은 DEEP LEARNING FOR ANOMALY DETECTION: A SURVEY 논문을 참고했음을 먼저 밝힙니다. Anomlay Detection Anomaly Detection는 '이상 탐지'라는 이름에서부터 알 수 있듯이 normal 하지 않은 데이터를 정상 데이터로부터 구분하는 것입니다. 그렇다면 어떤 데이터가 비정..